
JS零基础/CSS/前端入门教程手把手教你入门JavaWeb
以下内容是CSDN社区关于带参数抓取网页内容(动态网站)相关内容,如果想了解更多关于.NET社区社区其他内容,请访问...
2023-07-19
针对 httpclient4.* 绕验证码获取公司信息 包括 jsoup网页信息的爬虫及htmlUnit对动态网站信息的抓取
针对 httpclient4.* 绕验证码获取公司信息 包括 jsoup网页信息的爬虫及htmlUnit对动态网站信息的抓取
python爬虫系列(5.3-动态网站的爬取的策略)
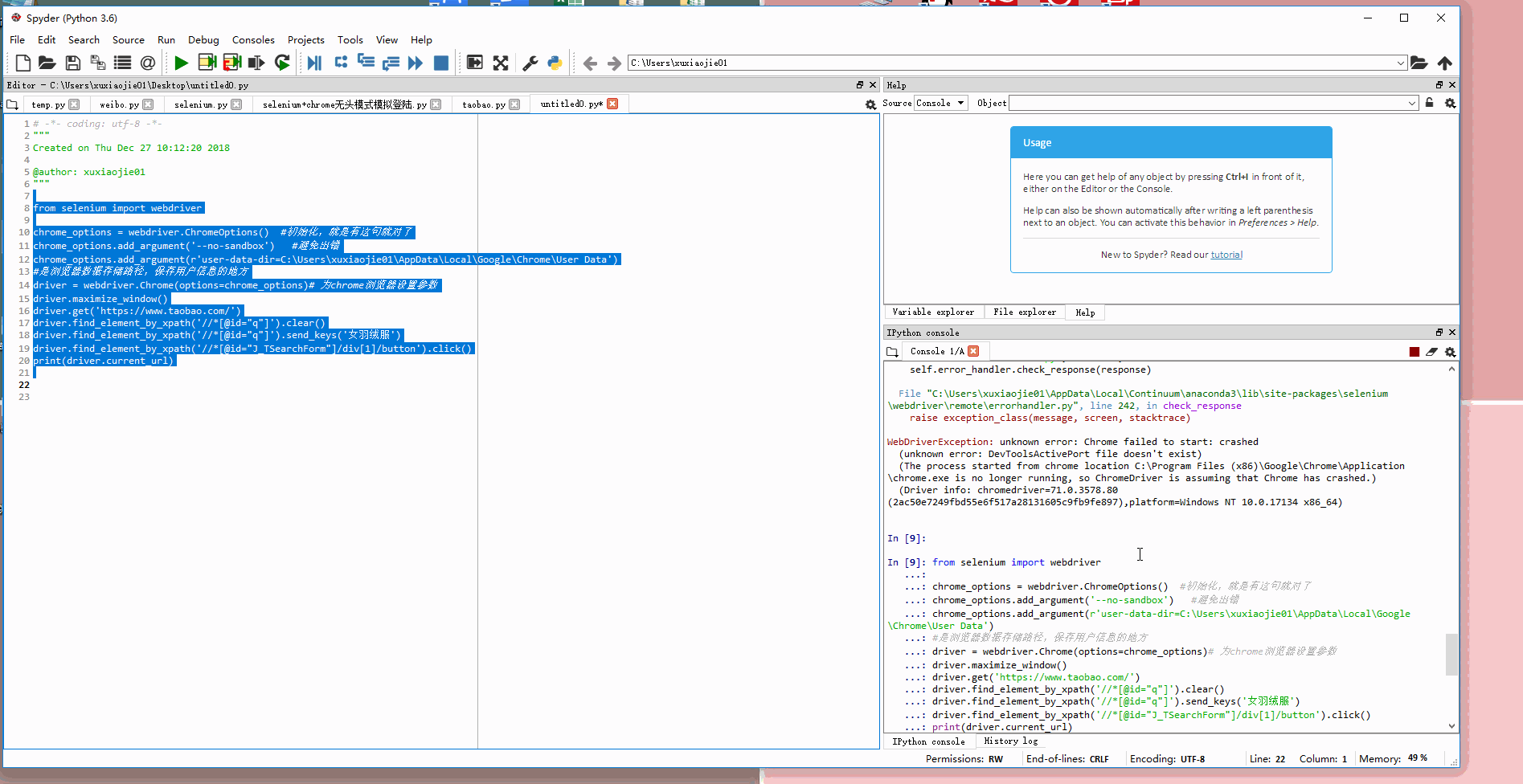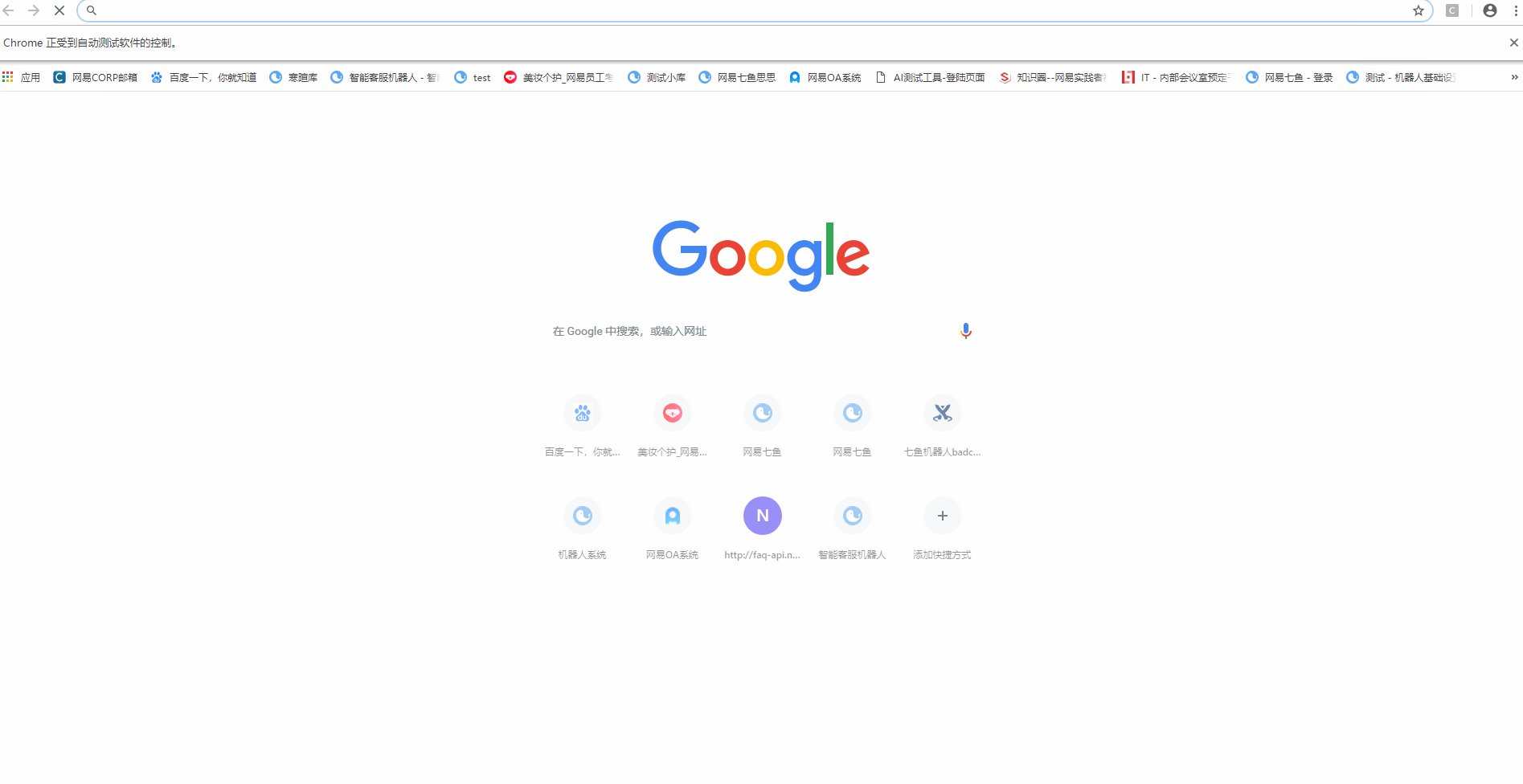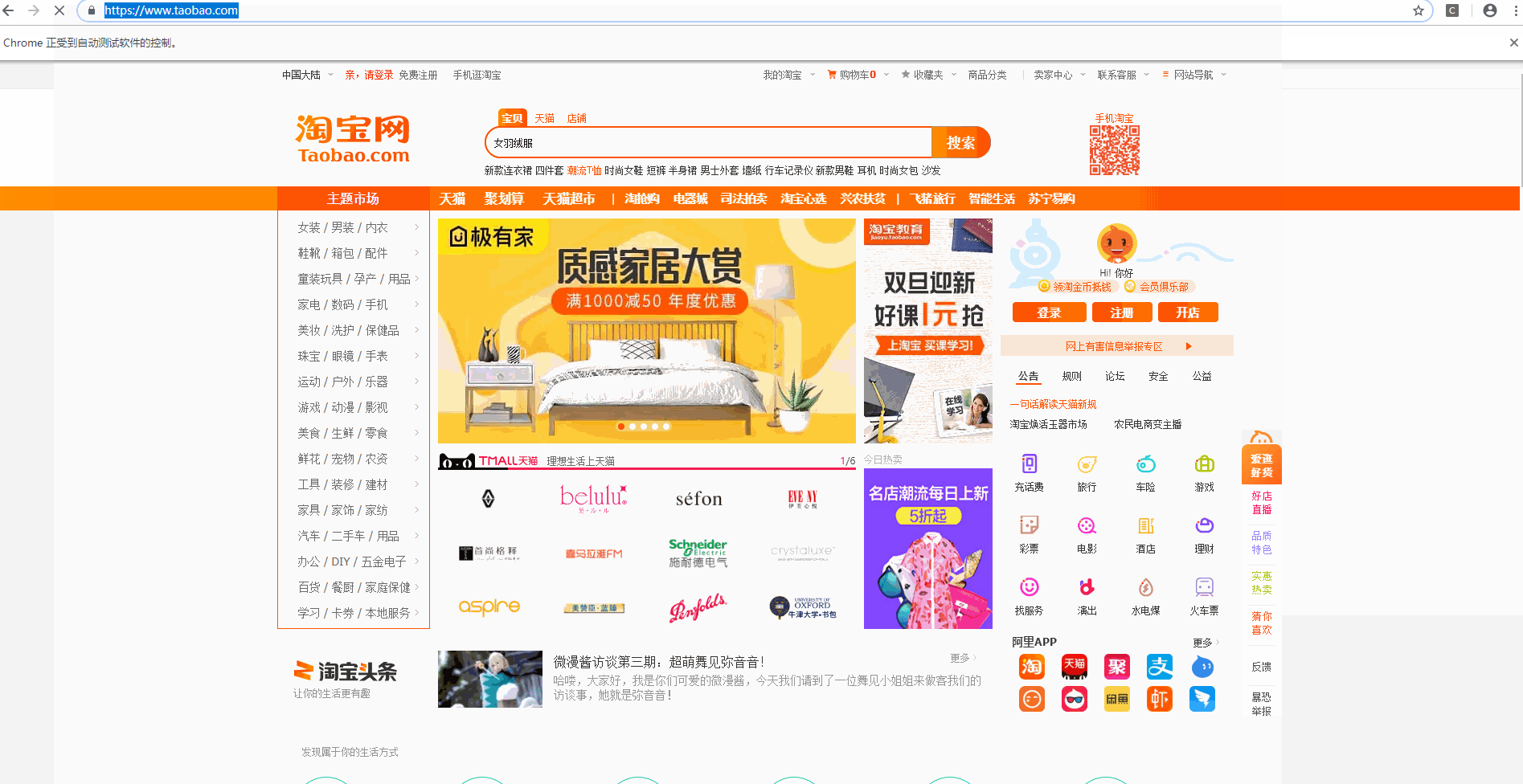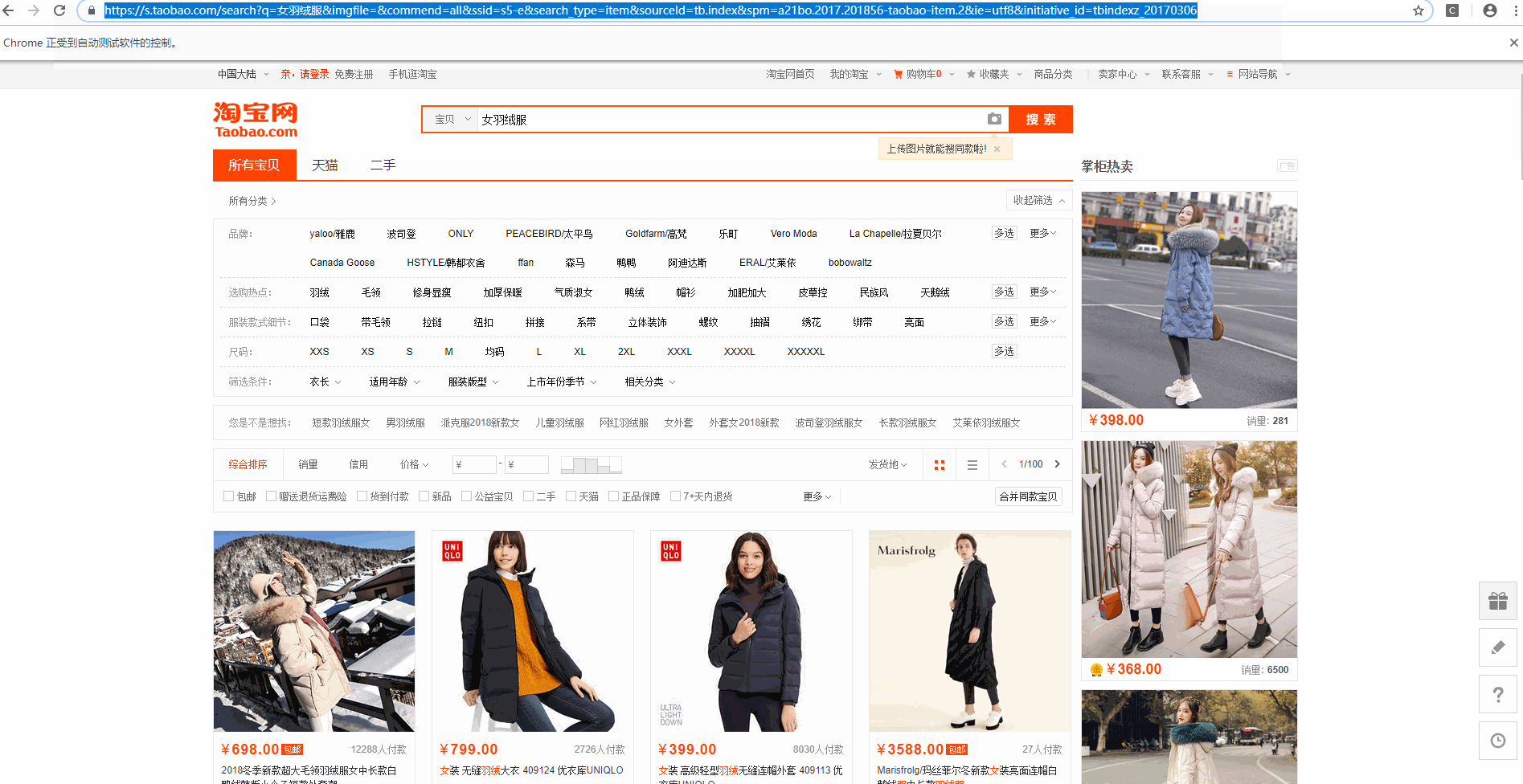
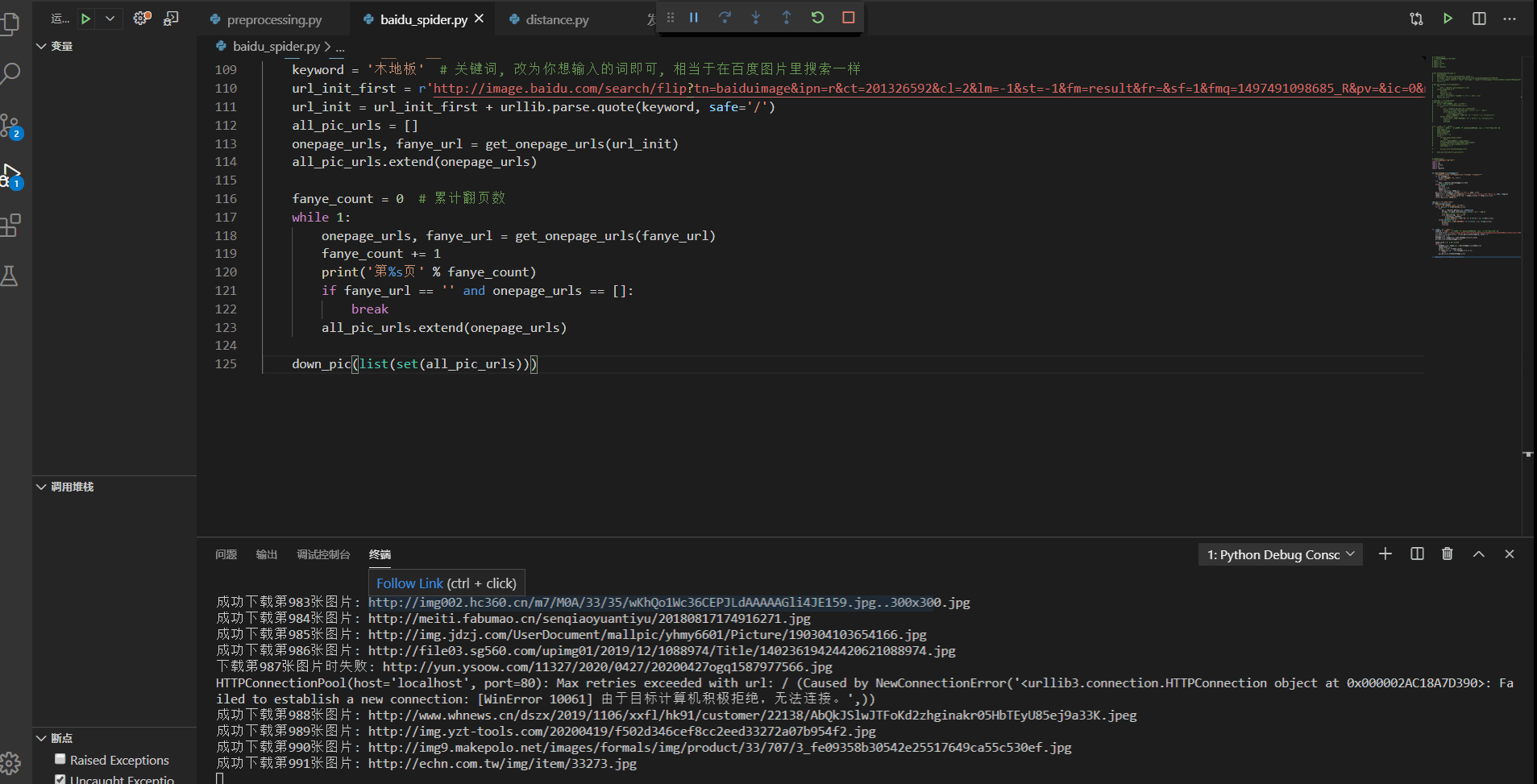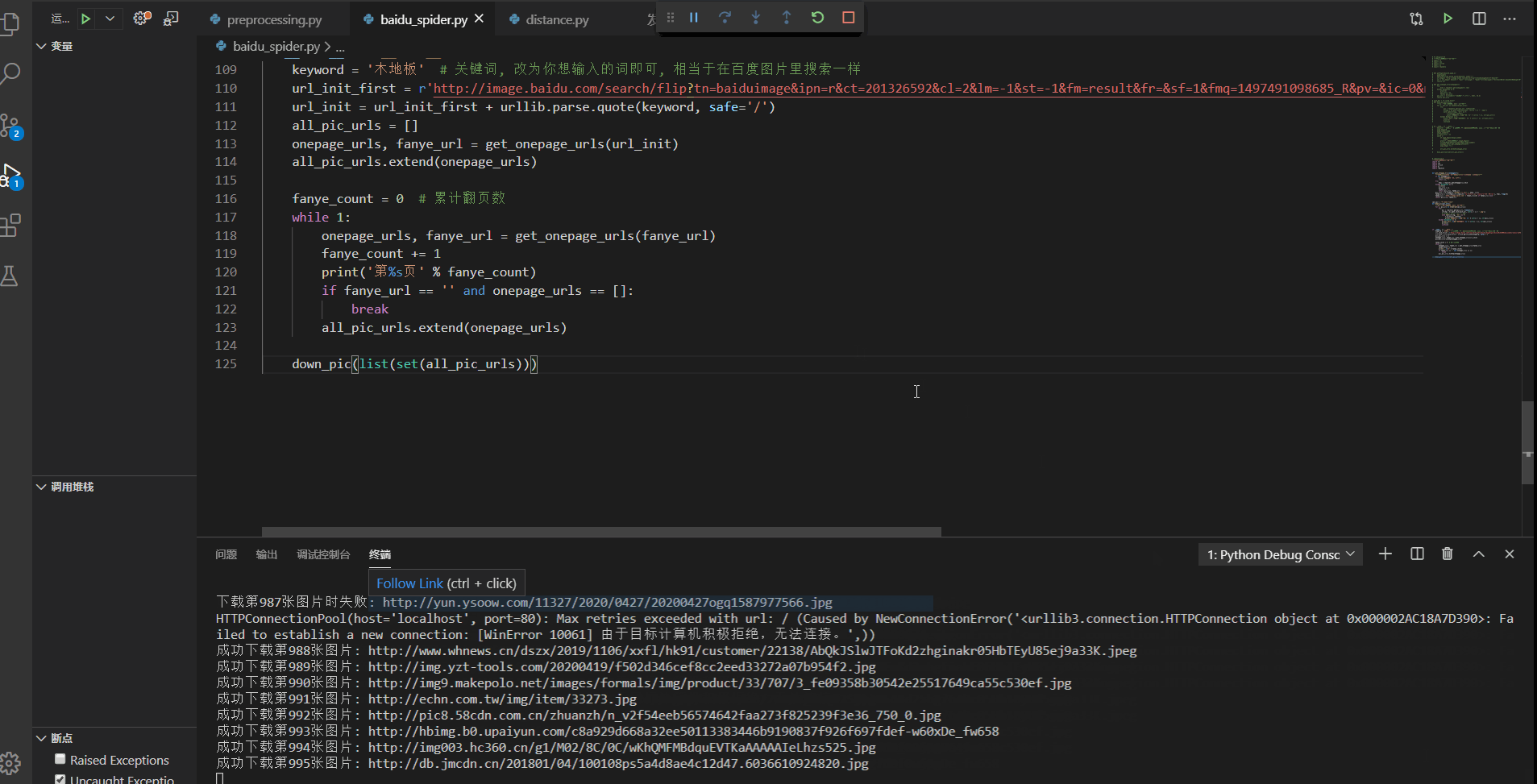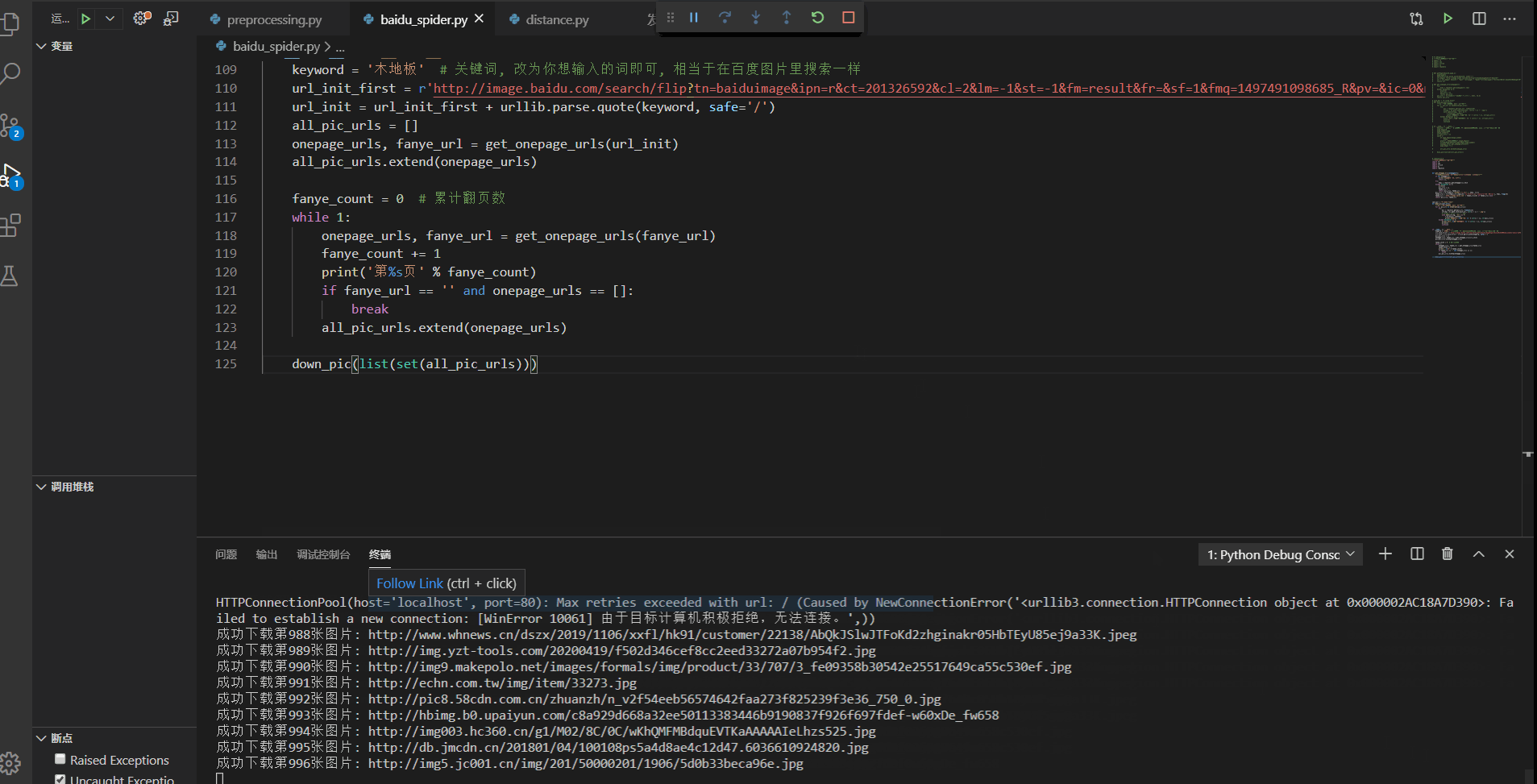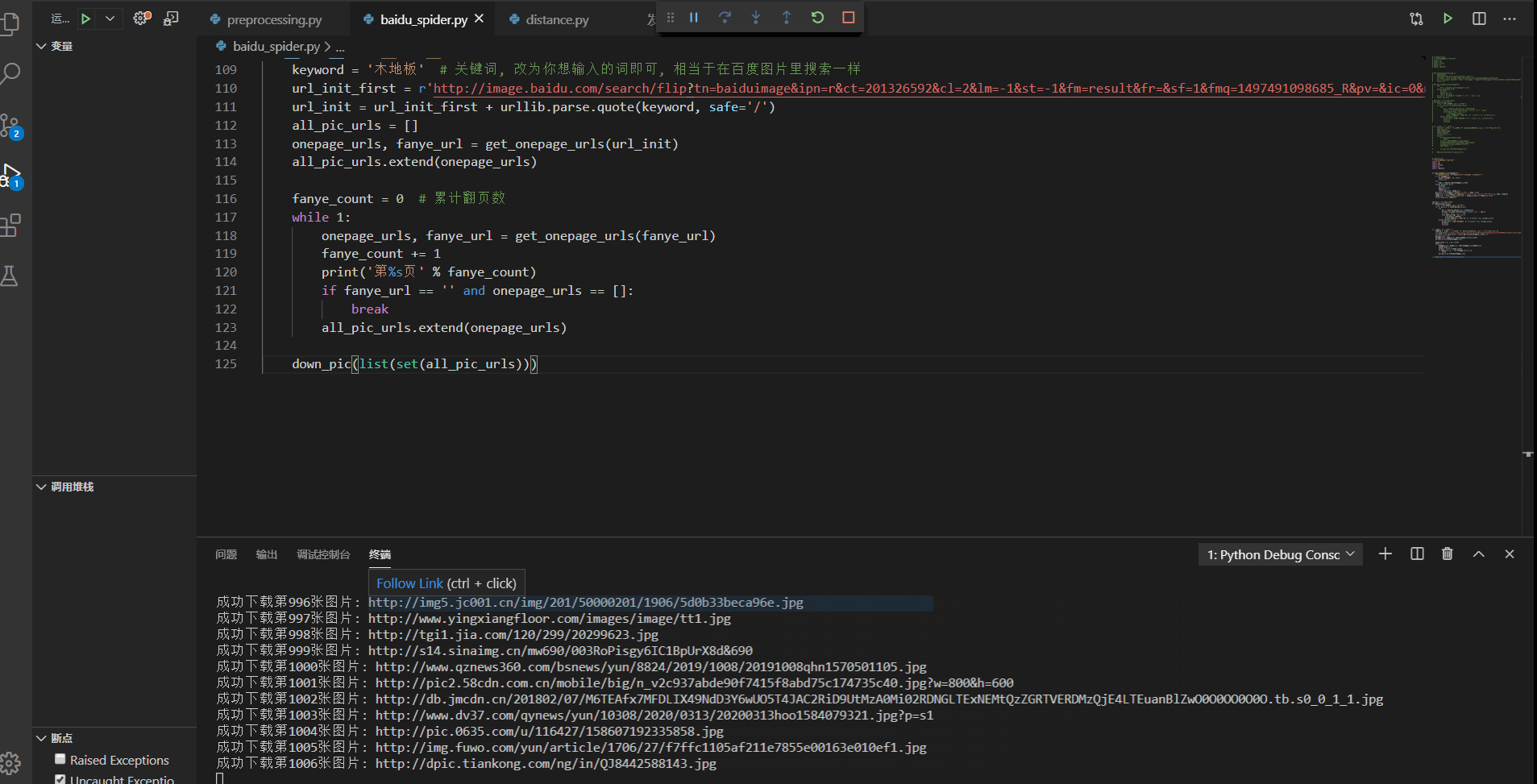
一、认识动态网站所谓的动态网站,是使用ajax加载出来的网页,我们打开网页的时候可以正常显示内容,但是我们在显示网页源代码的时候,里面却找不到该节点.二、常见动态网站的抓取方式1、直接分析ajax调用的接口,然后通过代码请求这个接口2、采用模拟浏览器请求该动态网站,然后获取网页数据一、分析网页数据请求二、使用requests库直接模拟请求数据from urllib import parseimpo...
Ae.Freezer:AC#库可抓取动态网站并将其转换为可通过CDN提供服务的静态内容
冷冻机AC#库可用于抓取动态网站并将其转换为可通过CDN提供服务的静态内容。冷冻机 AC#库可抓取动态网站并将其转换为静态内容,可通过Amazon S3与可选的CloudFront失效一起使用。 有关文档,请参见 。
零基础HTML/CSS/JS前端入门教程
手把手教你入门JavaWeb开发,用轻松愉快的方式,开启一段美妙的学习旅程。本课程主要包括最基础的前端知识,学习后可以独立开发简单的网页。最基础的JavaWeb知识,可以通过Java为网页提供动态服务。最基础的数据库知识,可以将关键信息进行长期存储。学习本门课程后可以了解JavaWeb开发的方方面面,可以独自开发一个简单的动态网站。
【Python全栈】第十周 Python网络爬虫基础
本周课程主要讲解Python网络爬虫的基础内容。具体有:Python中的正则表达式,网络爬虫基础介绍,爬虫的工作原理,urllib、urllib3和requests库的使用,GET和POST请求抓取数据实战,网络爬虫中常见错误的处理,以及网页信息解析库的使用(Xpath,BeautifulSoup,PyQuery)。
以下内容是CSDN社区关于带参数抓取网页内容(动态网站)相关内容,如果想了解更多关于.NET社区社区其他内容,请访问...

手机扫一扫
当前非电脑浏览器正常宽度,请使用移动设备访问本站!